KANANA 429 AI Safety
KANANA 429 활동으로 카카오 판교아지트에서 진행된 오프라인 밋업에 다녀왔습니다.

이번 밋업은 저녁 식사와 카카오 판교아지트 투어를 시작으로, 저녁 7시부터 9시까지 AI Safety와 Kanana Safeguard 세션, 조별 토론 순서로 진행되었습니다.
공간을 둘러보고 참여자들과 이야기를 나눈 뒤 세션이 이어지는 흐름이라, 전체 일정이 자연스럽게 이어졌습니다.
밋업 시작 전: 저녁 식사와 판교아지트 둘러보기
행사는 본격적인 세션 전에 저녁 식사로 시작되었습니다. 준비된 식사를 하면서 같은 활동에 참여하는 분들과 자연스럽게 이야기를 나눌 수 있었습니다.

식사 후에는 카카오 판교아지트를 둘러볼 수 있었습니다.
업무 공간을 지나 이동하는 동선이었는데, 실제로 사람들이 일하는 환경을 보면서 오늘 다룰 AI Safety가 단순한 개념이 아니라 서비스 운영과 연결된 문제라는 점을 조금 더 구체적으로 떠올려볼 수 있었습니다.
1부: 안전한 AI를 위한 카카오의 노력
저녁 7시부터 본격적인 세션이 시작되었습니다. 첫 번째 세션의 주제는 “안전한 AI를 위한 카카오의 노력”이었습니다.
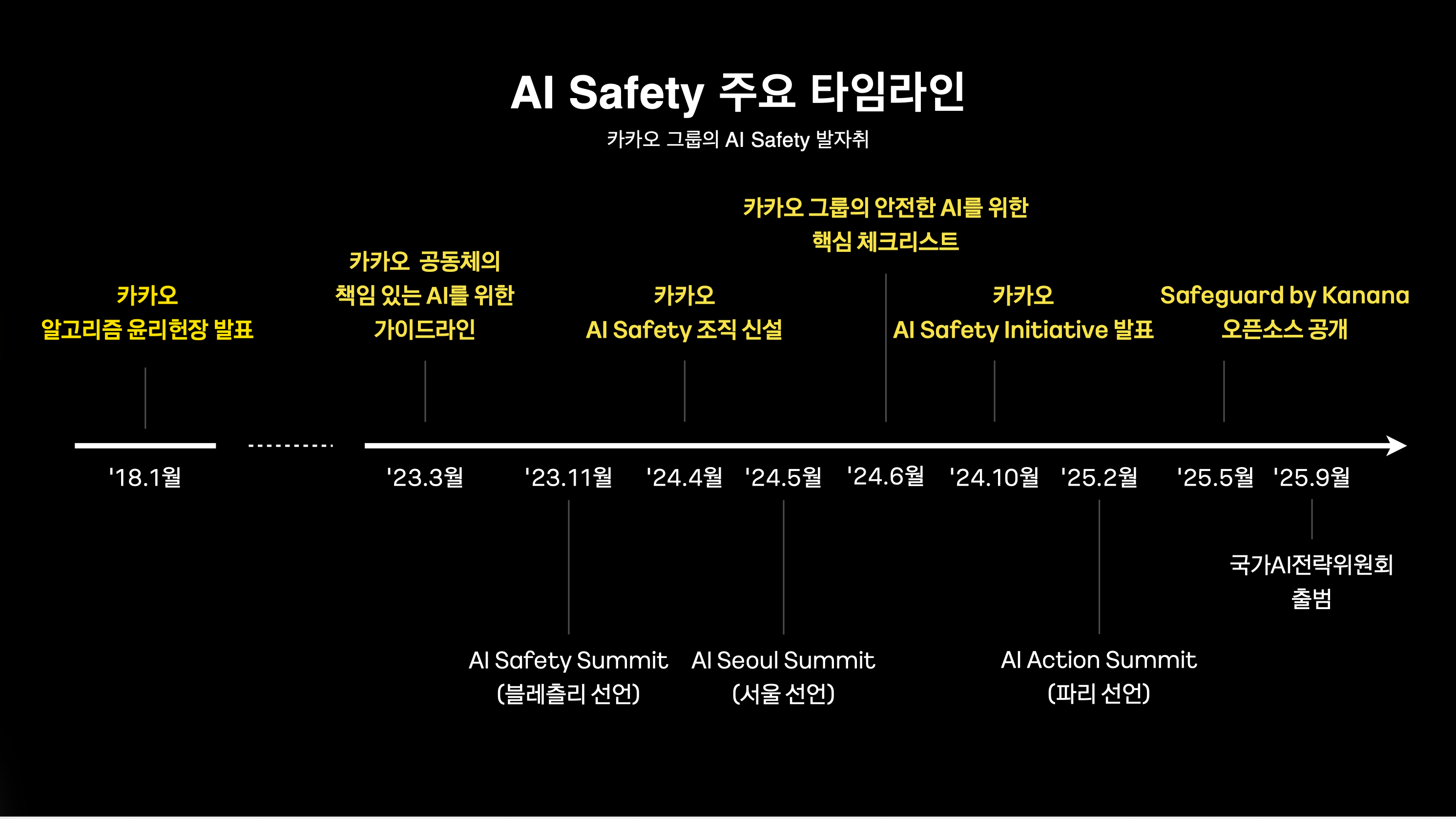
세션에서는 먼저 AI Safety가 왜 중요해졌는지에 대한 배경이 소개되었습니다. 생성형 AI가 일상과 서비스 전반에 빠르게 확산되면서, AI가 만들어내는 결과물이 사람들에게 어떤 영향을 줄 수 있는지에 대한 논의도 함께 커지고 있었습니다.
단순히 부정확한 답변을 줄이는 문제를 넘어,
악의적 사용, 오작동, 시스템 리스크처럼 더 넓은 범위의 문제를 함께 다뤄야 한다는 점이 강조되었습니다.
카카오는 이러한 문제를 해결하기 위해 AI 윤리 원칙과 리스크 관리 체계를 함께 마련하고 있었습니다.
리스크를 식별하고, 평가하고, 대응하는 흐름을 기반으로 AI를 운영하는 구조였고, 기술만으로 해결하기보다 정책과 거버넌스를 함께 가져가는 방식이었습니다.
이 부분에서는 AI Safety가 단일 기능으로 추가되는 것이 아니라,
서비스를 운영하는 과정 전반에 포함되어야 한다는 점을 알 수 있었습니다.
모델 성능을 높이는 것만큼이나,
사용자에게 어떤 방식으로 제공되고 어떤 기준으로 관리되는지도 중요하게 다뤄지고 있었습니다.
2부: Kanana Safeguard와 AI 가드레일
두 번째 세션에서는 국내 최초 오픈소스 AI 가드레일 모델인 Kanana Safeguard가 소개되었습니다.
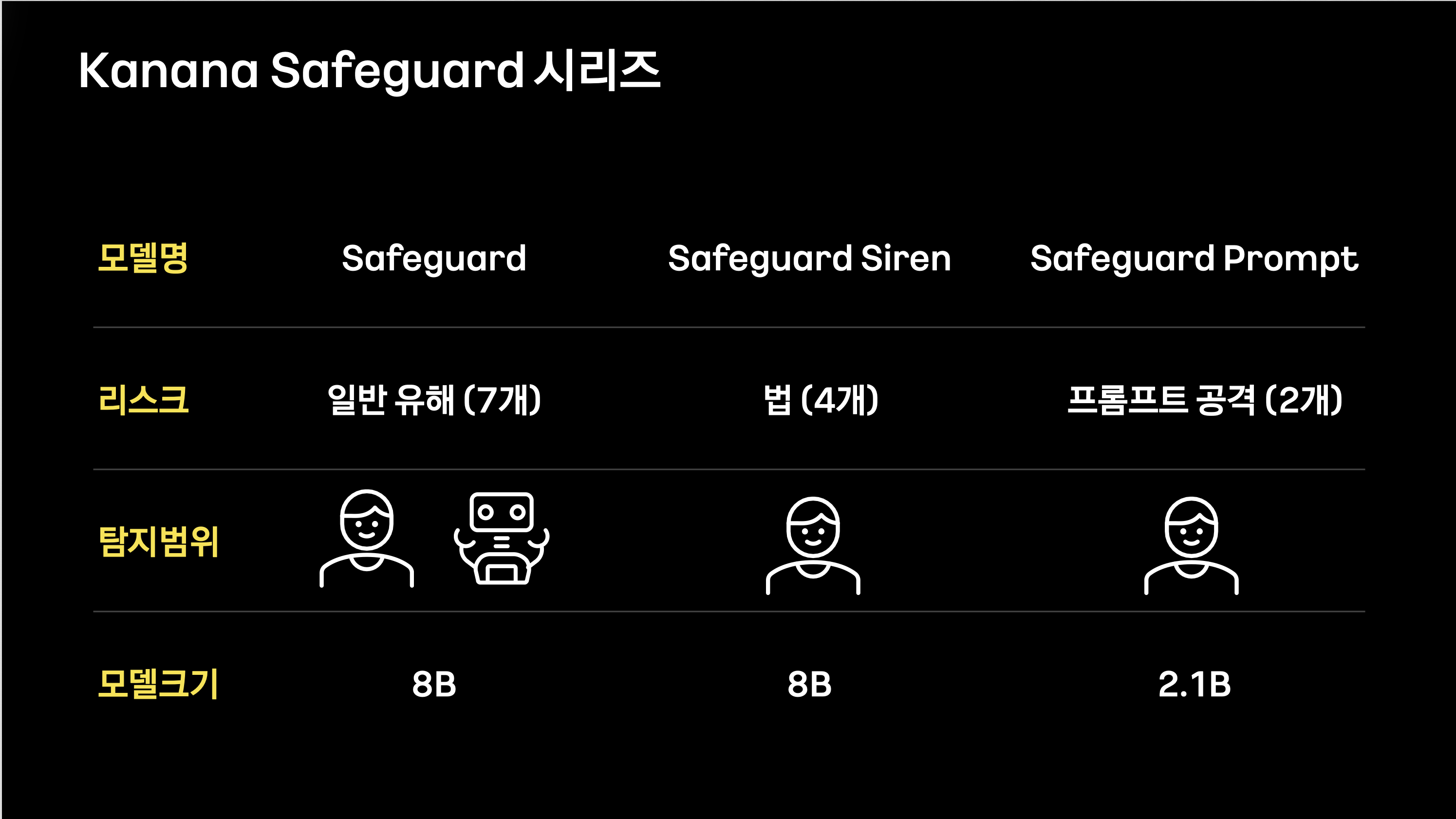
AI 가드레일은 AI가 사용자에게 위험하거나 부적절한 답변을 생성하지 않도록 돕는 안전 장치로 설명되었습니다.
Kanana Safeguard는 크게 세 가지 모델로 구성되어 있었습니다.
- Safeguard: 일반 유해 콘텐츠 탐지
- Safeguard Siren: 법적·정책적 리스크 탐지
- Safeguard Prompt: 프롬프트 공격 대응
이 구조에서 좋았던 점은 위험을 하나로 묶지 않고,
유형별로 나눠서 처리한다는 점이었습니다.
예를 들어 범죄나 자해처럼 명확하게 제한해야 하는 경우도 있지만,
의료나 법률처럼 “무조건 금지”보다는 “주의가 필요한 영역”도 있습니다.
Prompt Injection처럼 시스템 자체를 공격하는 문제도 별도로 다뤄야 합니다.
한국어와 한국 문화적 맥락을 반영한 데이터셋을 사용했다는 점이 기억에 남았습니다.
실제 서비스에서는 반말, 줄임말, 인터넷 표현, 은유적인 표현까지 섞여 들어오기 때문에
단순한 규칙 기반 필터로는 대응하기 어렵습니다.
흥미로웠던 부분은 결과를 <SAFE>, <UNSAFE-S4>처럼
단일 토큰 형태로 반환하는 구조였습니다.
3부: 토론 세션
마지막에는 조별 토론 세션이 진행되었습니다.

첫 번째 주제는 트롤리 딜레마였습니다.
선로를 바꿔 더 적은 수를 희생할 것인지, 개입하지 않을 것인지에 대한 선택을 두고 이야기를 나누었습니다.

두 번째 주제는 Anthropic의 Dario Amodei 사례였습니다.
AI 모델을 어디까지 공개할 것인지, 국가와 기업 사이에서 어떤 기준으로 판단해야 하는지에 대한 내용이었습니다.
토론은 정답을 찾기보다는 각자의 기준을 정리하는 방향으로 진행되었습니다.
맺음말
이번 밋업을 통해 AI를 바라보는 기준이 조금 달라졌습니다.
그동안은 모델이 얼마나 잘 맞히는지에 더 집중했다면,
이제는 이 모델이 실제 환경에서 어떤 영향을 줄 수 있는지도 함께 봐야 한다는 생각이 들었습니다.
어떤 요청을 허용할 것인지, 어디까지 제한할 것인지,
그리고 예상하지 못한 사용 방식에 어떻게 대응할 것인지까지 포함해서
AI를 설계해야 한다는 점을 다시 정리할 수 있는 시간이었습니다.