ML Systems Start
이 책 (Designing Machine Learning Systems) 을 요약 정리한 내용입니다.
2016년 11월, 구글은 자사의 다국어 신경망 기계번역 시스템을 Google Translate에 적용했다고 발표했는데, 이는 대규모 실제 서비스 환경에서 딥러닝 인공신경망이 성공적으로 활용된 최초의 사례 중 하나였습니다. 구글에 따르면, 이 업데이트를 통해 번역 품질은 이전 10년간의 개선을 모두 합친 것보다 더 큰 도약을 이루었다고 합니다.
그 이후 더 많은 기업들이 어려운 문제를 해결하기 위한 방안으로 ML을 채택하기 시작했습니다.
많은 사람들이 “머신러닝 시스템”이라고 하면, 로지스틱 회귀나 여러 형태의 신경망 같은 알고리즘만을 떠올립니다. 하지만 알고리즘은 실제 운영 환경에서의 ML 시스템 전체 중 극히 작은 부분에 불과합니다.
ML 시스템에는 프로젝트의 출발점이 된 비즈니스 요구사항, 사용자와 개발자가 시스템과 상호작용하는 인터페이스, 데이터 스택, 모델을 개발·모니터링·업데이트하는 로직, 그리고 이 로직을 제공할 수 있도록 지원하는 인프라가 모두 포함됩니다.
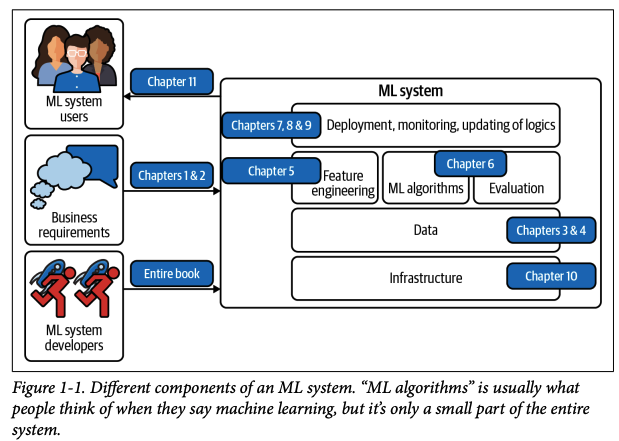
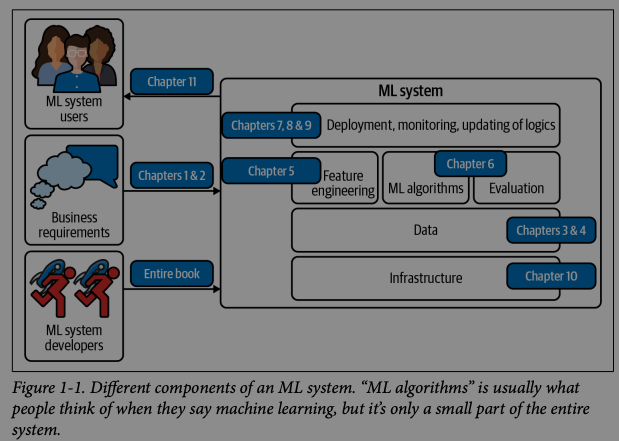
MLOps와 ML 시스템 설계의 관계
MLOps에서 Ops는 DevOps(Development + Operations, 개발 및 운영)에서 비롯되었습니다.
운영화(operationalize) 한다는 것은 어떤 것을 실제 운영 환경(production)으로 가져가는 것으로, 여기에는 배포, 모니터링, 유지관리가 포함됩니다.
MLOps는 ML을 운영 환경에 도입하기 위한 도구와 모범사례들의 집합이라고 볼 수 있습니다.
ML 시스템 설계는 MLOps를 시스템적 관점에서 바라보는 것입니다. ML 시스템을 전체적으로 고려하여 주어진 목표와 요구사항을 충족하도록 설계하는 것입니다.
Goals
많은 훌륭한 책들이 다양한 ML 알고리즘을 다루지만, 이 책은 특정 알고리즘 자체를 깊게 다루지 않습니다. 대신 ML 시스템 전체를 이해하도록 돕습니다. 어떤 알고리즘을 쓰든 간에 주어진 문제에 가장 적합한 해결책을 설계할 수 있는 프레임워크를 제공합니다.
알고리즘은 빠르게 구식이 될 수 있지만, 시스템적 프레임워크는 새로운 알고리즘이 나오더라도 여전히 적용 가능하기 때문입니다.
첫 장에서는 ML 모델을 운영 환경에 배포하기 위해 필요한 것들의 개요를 제공합니다. 본격적으로 ML 시스템을 개발하는 법을 논하기 전에, 가장 근본적인 질문인 “언제 ML을 쓰고, 언제 쓰지 말아야 하는가?”를 먼저 다룹니다.
머신러닝을 언제 사용할 것인가
ML이 적용 가능한 문제라 하더라도 항상 최적의 해결책이 아닐 수 있습니다. ML 프로젝트를 시작하기 전에, ML이 반드시 필요한지, 비용 대비 효과적인지를 물어야 합니다.
머신러닝은 기본적으로 다음과 같은 작업을 수행한다:
- 학습: 시스템이 무언가를 학습할 수 있는 능력이 있어야 한다.
- 복잡한 패턴: 학습할 패턴이 존재하고, 그것이 복잡할 때 유용하다.
- 기존 데이터: 데이터를 학습 자료로 사용할 수 있어야 한다.
- 예측: ML은 본질적으로 예측 문제를 다룬다.
- 보지 못한 데이터: 학습 데이터와 비슷한 분포를 가진 새로운 데이터에 대해 잘 동작해야 한다.
또한 ML이 특히 잘 맞는 문제의 특성은 다음과 같습니다:
- 반복적인 문제
- 잘못된 예측의 비용이 낮은 문제
- 대규모로 활용 가능한 문제
- 패턴이 계속 변화하는 문제
반대로, 다음과 같은 경우 ML은 적합하지 않습니다:
- 윤리적으로 문제가 되는 경우
- 더 단순한 해법이 존재하는 경우
- 비용 대비 효과가 없는 경우
머신러닝 활용 사례
ML은 소비자 애플리케이션과 기업 애플리케이션 모두에서 폭발적으로 활용되고 있습니다.
- 소비자 분야: 추천 시스템(Amazon, Netflix), 검색, 예측 입력, 사진 보정, 지문·얼굴 인식, 번역, 스마트 비서, 보안 카메라, 건강 모니터링 등.
- 기업 분야: 사기 탐지, 가격 최적화, 수요 예측, 고객 획득 비용 절감, 이탈(churn) 예측, 고객 지원 티켓 분류, 브랜드 모니터링, 감성 분석, 헬스케어 진단 보조 등.
기업용 ML은 소비자용보다 정확성 요구가 높고 지연(latency)에는 관대한 편입니다.
연구 단계의 ML vs 운영 단계의 ML
연구와 운영 환경의 ML은 다릅니다. 연구에서는 성능 극대화가 목표지만, 운영에서는 다양한 요구사항을 충족해야 합니다.
| 구분 | 연구(Research) | 운영(Production) |
|---|---|---|
| Requirements | SOTA 성능 | 이해관계자마다 서로 다른 요구사항 |
| Computational priority | 빠른 학습, 높은 처리량 | 빠른 추론, 낮은 지연시간 |
| Data | 정적(Static) | 끊임없이 변동(Shifting) |
| Fairness | 보통 고려되지 않음 | 반드시 고려해야 함 |
| Interpretability | 보통 고려되지 않음 | 반드시 고려해야 함 |
예: 음식점 추천 앱
- ML 엔지니어: 사용자가 클릭할 확률이 높은 음식점 추천 원함
- 영업팀: 가격이 비싼 음식점 추천 원함
- 제품팀: 100ms 이하의 응답 속도 원함
- ML 플랫폼팀: 시스템 안정성을 우선시
- 매니저: 수익성 극대화
이처럼 연구와는 달리 각 팀의 요구사항이 다르고 서로 충돌합니다.
전통적 소프트웨어와 ML 시스템의 차이
전통적 SW는 코드와 데이터가 분리되어 있지만, ML은 코드+데이터+모델 산출물이 결합됩니다.
따라서 ML 시스템은 다음과 같은 고유한 어려움을 가집니다:
- 데이터 버전 관리와 품질 관리 필요
- 데이터 불균형 및 노이즈 문제
- 대규모 파라미터 모델의 배포·운영 문제
- 해석 가능성과 공정성 문제
- 운영 환경에서의 모니터링과 디버깅 난이도
맺음말
이 책에서는 알고리즘 중심이 아니라 시스템 중심의 접근을 취하며, ML 시스템을 전체적으로 설계하고 운영하는 방법을 제시합니다.
Do not choose an AI tool for your study. First, define method to solve the problem then, consider AI or ML only if necessary.